Evan Dong

Introduction
Human motion capture has numerous application in human-robot interaction, law enforcement, surveillance, entertainment, sports, medicine, etc. Various methods have been developed to date and they can be categorized into: marker-based or markerless; articulated model-based or appearance-based; single view or multiple view; and so on. Marker-based methods are the simplest ones and therefore are also the methods with most success so far. However, it is obviously not always possible to add markers to the human subjects, and markerless approaches are without a doubt the most general and desirable methods.
In our work, we explore markerless method for human motion capture. We propose a Bayesian estimation based method which falls into single view and articulated model-based category. The estimator, derived from Particle Filters, was expanded to a hierarchical model by introducing a new coarse-to-fine framework to deal with the computational complexity inherent to Particle Filters.
Results
Since the estimation of human pose from single view is restrictive to specific class of human motion, we tested our proposed method using partial frames of "Combo" and "Gesture" sequence in HumanEva I Dataset.
1. Estimation results for "Combo_S1"
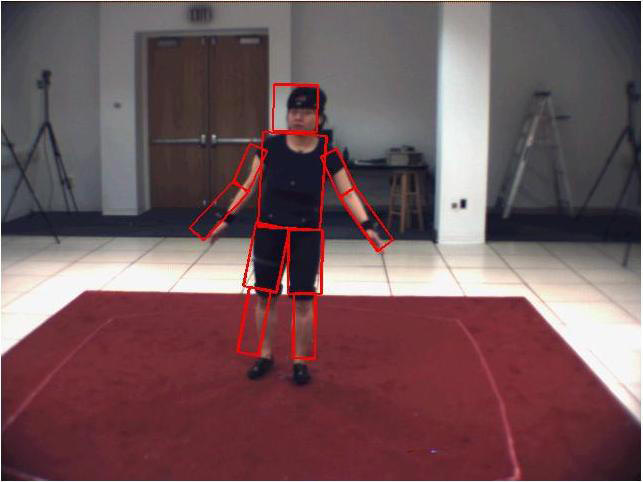



Pose estimation at "coarse" level




Pose estimation at "fine" level
2. Estimation results for "Combo_S2"
3. Estimation results for "Combo_S3"
4. Estimation results for "Combo_S4"
5. Estimation results for "Gesture_S1"
6. Estimation results for "Gesture_S2"
7. Estimation results for "Gesture_S3"
8. Estimation results for "Gesture_S4"