






in our research, we developed two phenotyping platforms for in-situ characterization of plant responses to changes in their environment (e.g., management practices, drought, flood, heat, etc.). These platforms consist of two robotic systems: a mobile, observation tower, Vinoculer, for canopy characterization and general inspection of the crop; and a ground vehicle, Vinobot, for individual plant phenotyping.

Figure above shows the Vinobot and Vinoculer in a field at the Bradford Research Center near Columbia, Missouri, USA.
Vinobot (ViGIR-lab Phenotyping Robot) is a mobile platform equipped with a range of sensors designed to fulfill both the phenotyping tasks and its autonomous navigation needs.

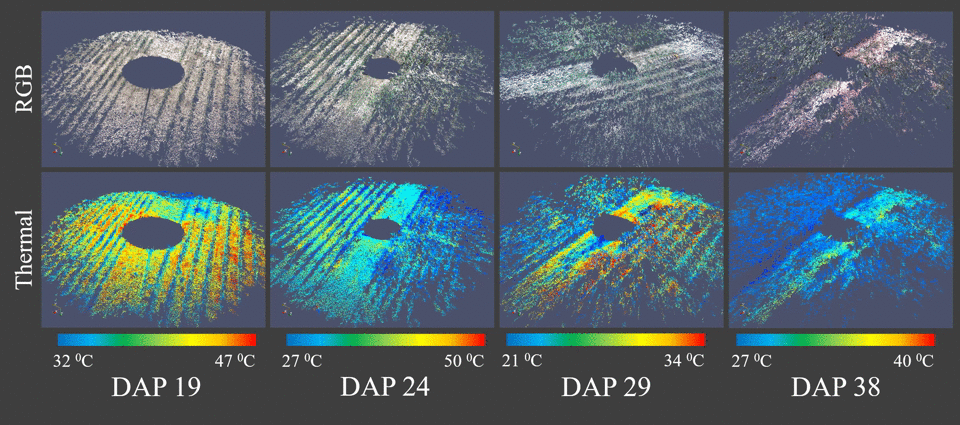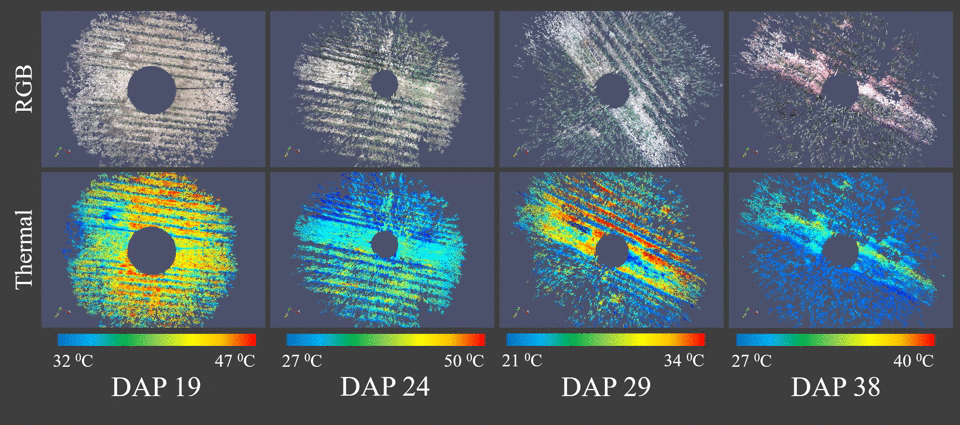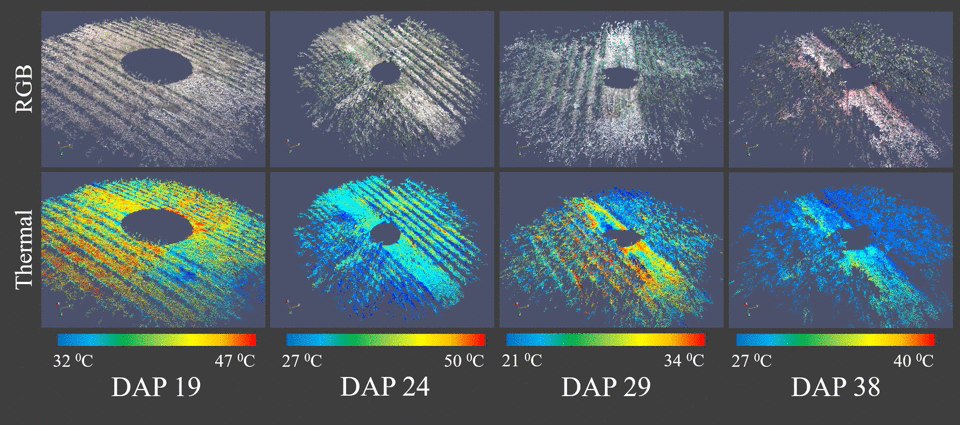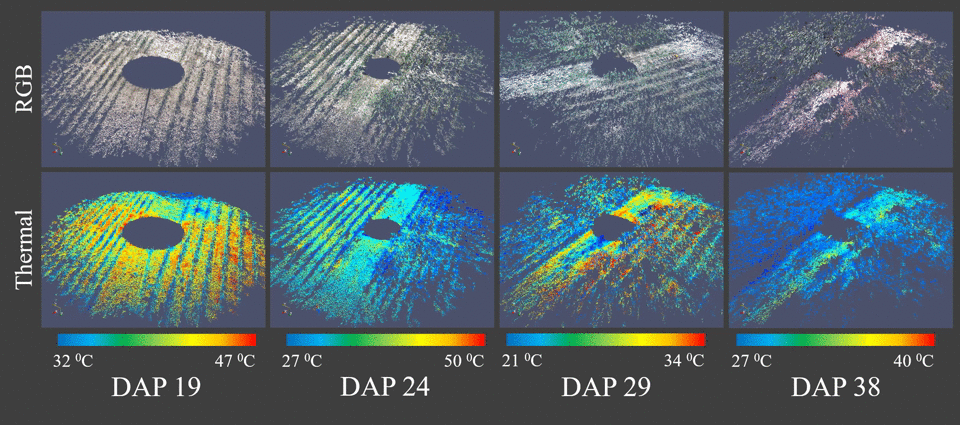
Vinoculer (ViGIR-lab Phenotyping Trinocular Observer) is a portable observation tower mounted in the center of a field. It is capable of turning 360 degrees while capturing data from a large area. To see live stream from the vinoculer click here. It was equipped with stereo RGB and IR cameras in order to perform measurements such as volume, leaf area, biomass, height, growth rate and other canopy characteristics.

Together, the Vinobot and Vinoculer are capable of collecting data from a large area at the canopy and individual plant level.
We proposed the use of a trinocular camera rig consisting of a stereo RGB pair plus a thermal camera (Vinoculer) to create multi-dimensional models of the plants in the field. That is, our system allows both appearance and temperature information to be stored and analyzed for plant phenotyping purposes. We refer to it as a 4D-RGB model, since structural (3D), thermal (+1D) and textural (RGB) information are accurately registered and stored.
Foreground object detection is an essential task in many image processing and image understanding algorithms, in particular for video surveillance. Background subtraction is a commonly used approach to segment out foreground objects from their background. In real world applications, temporal and spatial changes in pixel values such as due to shadows, gradual/sudden changes in illumination, etc. make modeling backgrounds a quite difficult task.


In our work, we propose an adaptive learning algorithm of multiple subspaces (ALPCA) to handle sudden/gradual illumination variations for background subtraction.
Human motion capture has numerous application in human-robot interaction, law enforcement, surveillance, entertainment, sports, medicine, etc. Various methods have been developed to date and they can be categorized into: marker-based or markerless; articulated model-based or appearance-based; single view or multiple view; and so on. Marker-based methods are the simplest ones and therefore are also the methods with most success so far. However, it is obviously not always possible to add markers to the human subjects, and markerless approaches are without a doubt the most general and desirable methods.


In our work, we explore markerless method for human motion capture. We propose a Bayesian estimation based method which falls into single view and articulated model-based category. The estimator, derived from Particle Filters, was expanded to a hierarchical model by introducing a new coarse-to-fine framework to deal with the computational complexity inherent to Particle Filters.
Any control system using visual-sensory feedback loops falls into one of four categories. These categories are derived from choices made regarding two criteria: the coordinate space of the error function, and the hierarchical structure of the control system. These choices will determine whether the system is a position-based or an image-based system, as well as if it is a dynamic look-and-move or a direct visual servo.
In our work, we present an image-based, dynamic look and move visual servoing system. The difference between our approach and other popular ones is in the use of quaternion representation, which eliminates the potential singularities introduced by a rotational matrix representation.
